Scene Coordinate Reconstruction
Posing of Image Collections via Incremental Learning of a Relocalizer
ECCV 2024 (Oral)
Eric Brachmann1
Jamie Wynn1
Shuai Chen2
Tommaso Cavallari1
Áron Monszpart1
Daniyar Turmukhambetov1
Victor Adrian Prisacariu1,2
1Niantic 2Abstract
We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis.
Watch a 3-minute overview video
Watch ACE Zero reconstruct some scenes
We visualize the reconstruction process of ACE Zero for some of the scenes form our experiments. During each reconstruction, we show the point cloud extracted from the current implicit scene model. At the end of each reconstruction, we switch to a point cloud extracted from a Nerfacto model trained on top of the ACE Zero camera poses. Use the controls to switch between scenes.
How does ACE Zero work?
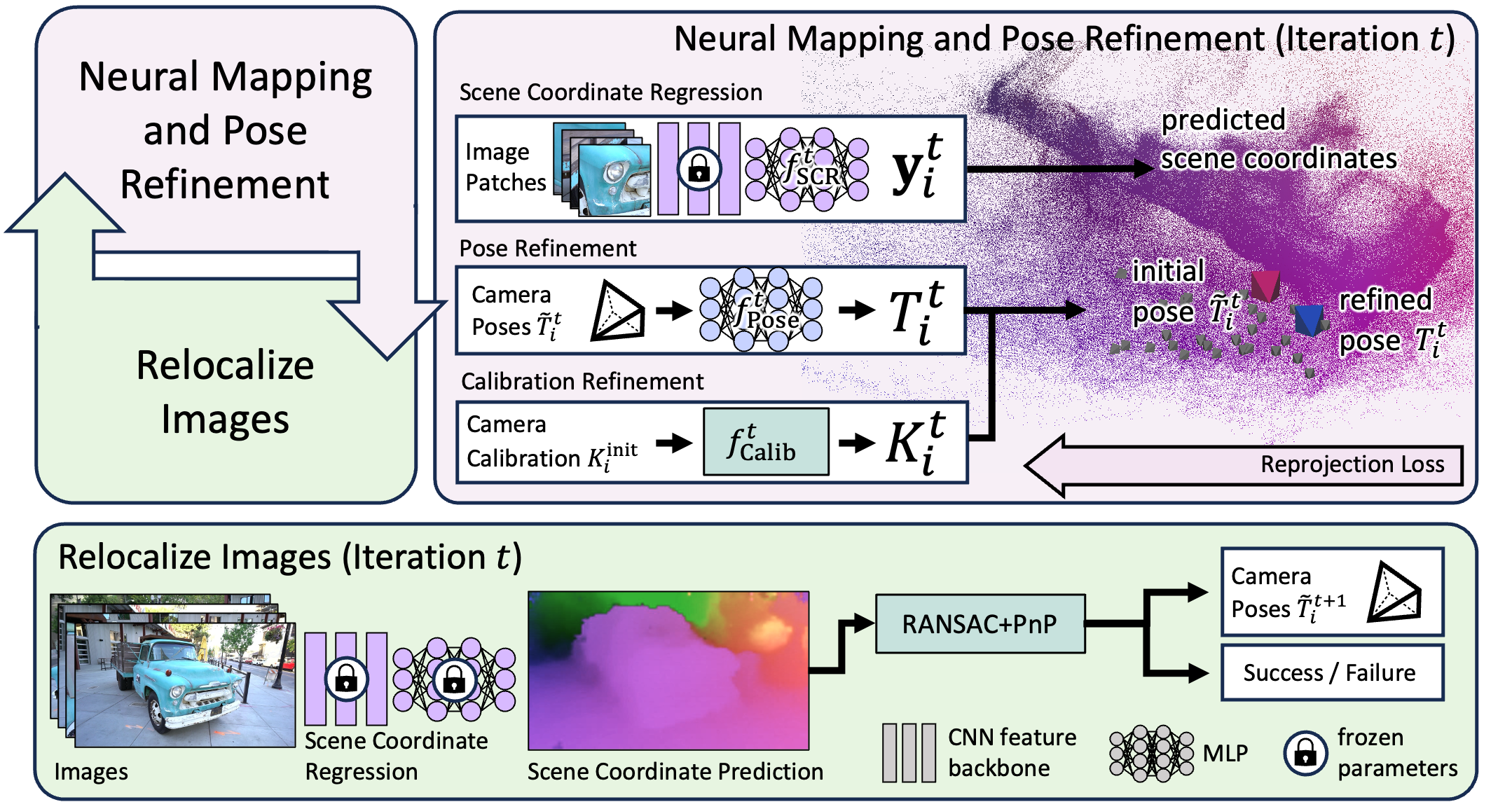
Top left: We loop between learning a reconstruction from the current set of images and poses ("neural mapping"), and estimating poses of more images ("relocalization"). Top right During the mapping stage, we train an ACE scene coordinate regression network as our scene representation. Camera poses of the last relocalization round and camera calibration parameters are refined during this process. We visualize scene coordinates by mapping XYZ to the RGB cube. Bottom: In the relocalization stage, we re-estimate poses of images using the scene coordinate regression network, including images that were previously not registered to the reconstruction. If the registration of an image succeeds, it will be used in the next iteration of the mapping stage; otherwise it will not.
ACE Zero poses allow for novel view synthesis
We showcase the robustness of ACE Zero, and the accuracy of its estimated poses, via novel view synthesis. In particular, we reconstruct a scene using ACE Zero, and then train a Nerfacto model on top of the final camera pose estimates. Novel view synthesis is also the foundation of the quantitative benchmark in our paper.
ACE Zero compares favourably to previous SfM approaches
We compare ACE Zero to previous learning-based SfM approaches via novel view synthesis. NoPe-NeRF needs a long time to converge. We run it on 200 images per scene which still takes two days per scene. DUSt3R quickly runs out of GPU memory. We were able to run it with 50 frames per scene on a A100 GPU (40GB). ACE Zero can process multiple thousand images per scene efficiently, in terms of time and memory.
ACE Zero estimates poses very similar to COLMAP. We show COLMAP poses (for Tanks & Temples and Mip-NeRF 360) and KinectFusion (for 7-Scenes) in orange and ACE Zero poses in green.
ACE Zero offers attractive running times while enabling view synthesis quality comparable to COLMAP.
Please consider citing our paper
@inproceedings{brachmann2024acezero,
title={Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer},
author={Brachmann, Eric and Wynn, Jamie and Chen, Shuai and Cavallari, Tommaso and Monszpart, {\'{A}}ron and Turmukhambetov, Daniyar and Prisacariu, Victor Adrian},
booktitle={ECCV},
year={2024},
}