Abstract
For augmented reality (AR), it is important that virtual overlays appear to "sit among" real world objects. The virtual element should variously occlude and be occluded by real matter, based on a plausible depth ordering. This occlusion should be consistent over time as the viewer's camera moves. Unfortunately, small mistakes in the estimated scene depth can ruin the downstream occlusion mask, and thereby the AR illusion. Especially in real-time settings, depths inferred near boundaries or across time can be inconsistent. In this paper, we challenge the need for depth-regression as an intermediate step.
We instead propose an implicit model for depth and use that to predict the occlusion mask directly. The inputs to our network are one or more color images, plus the known depths of any virtual geometry. We show how our occlusion predictions are more accurate and more temporally stable than predictions derived from traditional depth-estimation models. We obtain state-of-the-art occlusion results on the challenging ScanNetv2 dataset and superior qualitative results on real scenes.
Video
You might need to hit play!
Overview
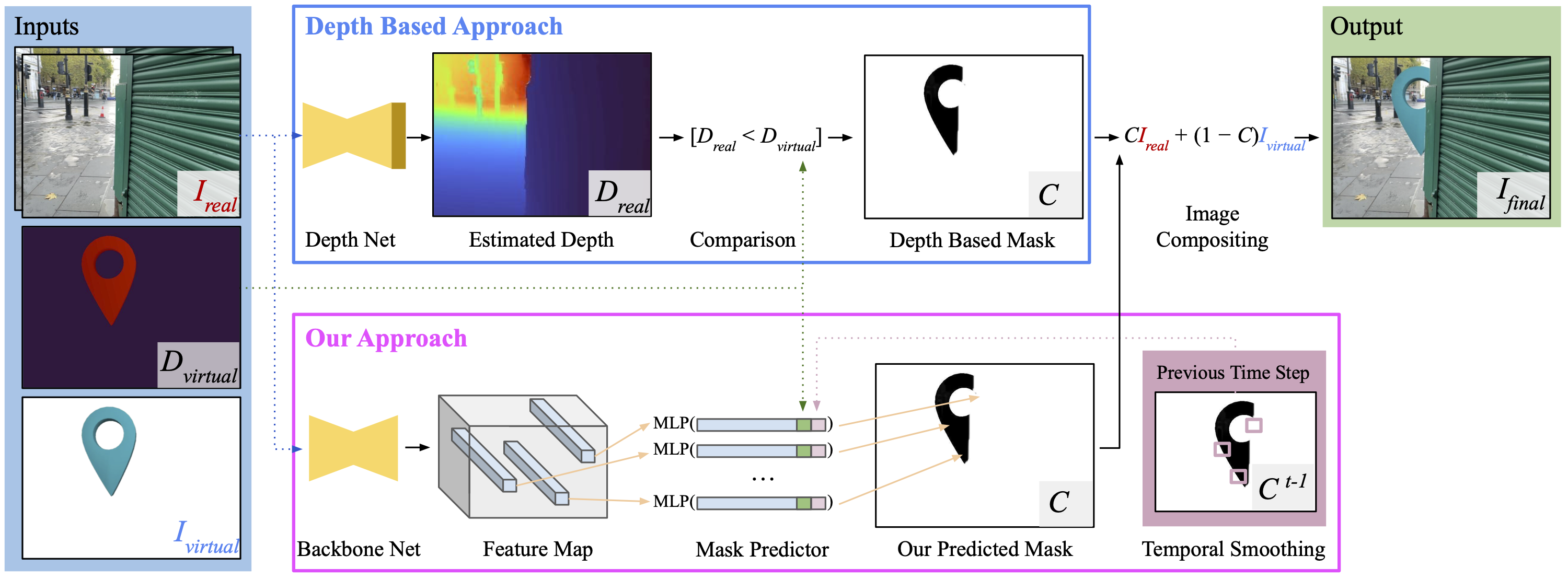
Given RGB images of a real scene, and renderings of a virtual asset, our aim is to realistically composite the virtual asset into the scene. Top: Conventional approaches first estimate a depth map from the real image(s), before comparing each pixel with the virtual depth to generate a compositing mask C. Bottom: We instead directly estimate the mask given the real image(s) and virtual depth as input. Additionally, our method also employs a lightweight temporal smoothing input to generate more stable predictions.
Qualitative Comparisons
Citation
If you find this work useful for your research, please cite:
@inproceedings{watson-2023-implicit-depth,
title = {Virtual Occlusions Through Implicit Depth,
author = {Jamie Watson and
Mohamed Sayed and
Zawar Qureshi and
Gabriel J. Brostow and
Sara Vicente and
Oisin Mac Aodha and
Michael Firman},
booktitle = {CVPR},
year = {2023}
}
Acknowledgements
Many thanks to Daniyar Turmukhambetov, Jamie Wynn, Clément Godard and Filippo Aleotti for their valuable help and suggestions.
© This webpage was in part inspired by this template.