Training Dataset Creation
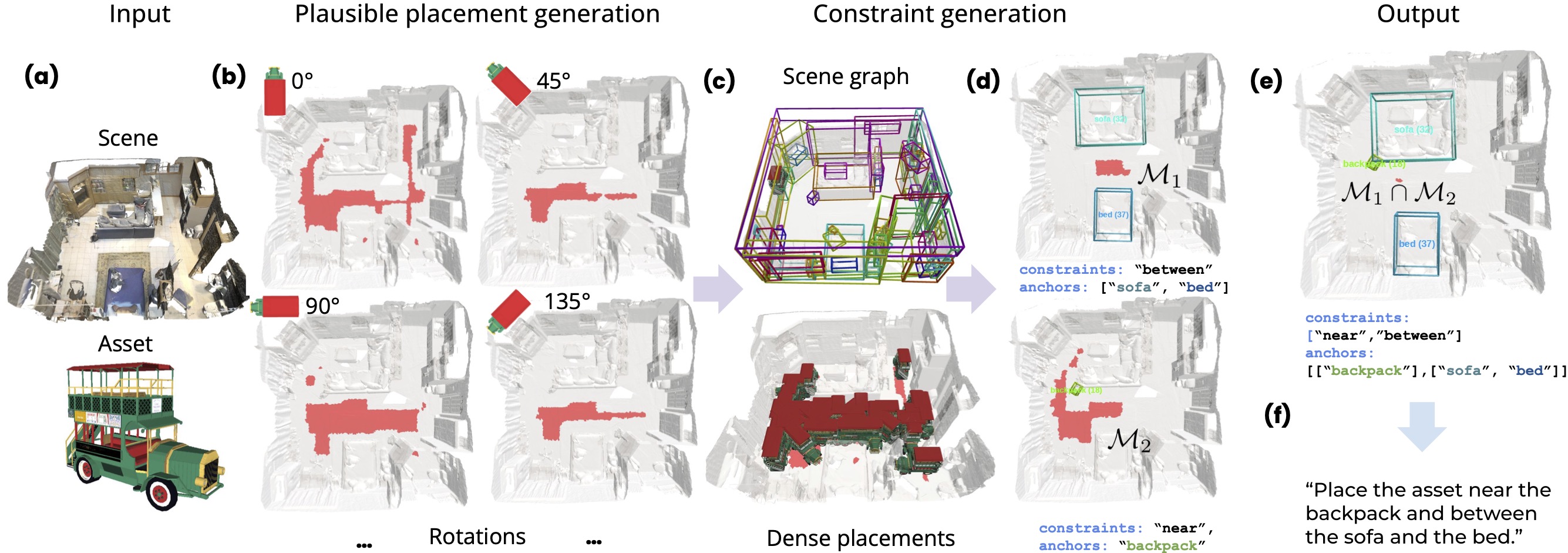
Given a scene and an asset as input (a) the goal is to create a prompt (f) and corresponding mask M of valid placements (e). We start by finding the set of points which are physically plausible placements, shown in red in (b). We consider eight equally spaced rotation angles, which condition the valid placements. For this example, angle 0◦ has more valid placements than 45◦. To generate the language constraints, we use the ground truth scene graph (c). Object anchors are selected from the scene graph and combined with relationship types to create a constraint and corresponding validity mask (d). The different placement constraints are combined in the final output by intersecting the validity masks (e) given a mask of valid dense placements. Based on each selected set of anchors and constraint relationships, a natural language prompt is created using templates (please, see supplemental for more details).