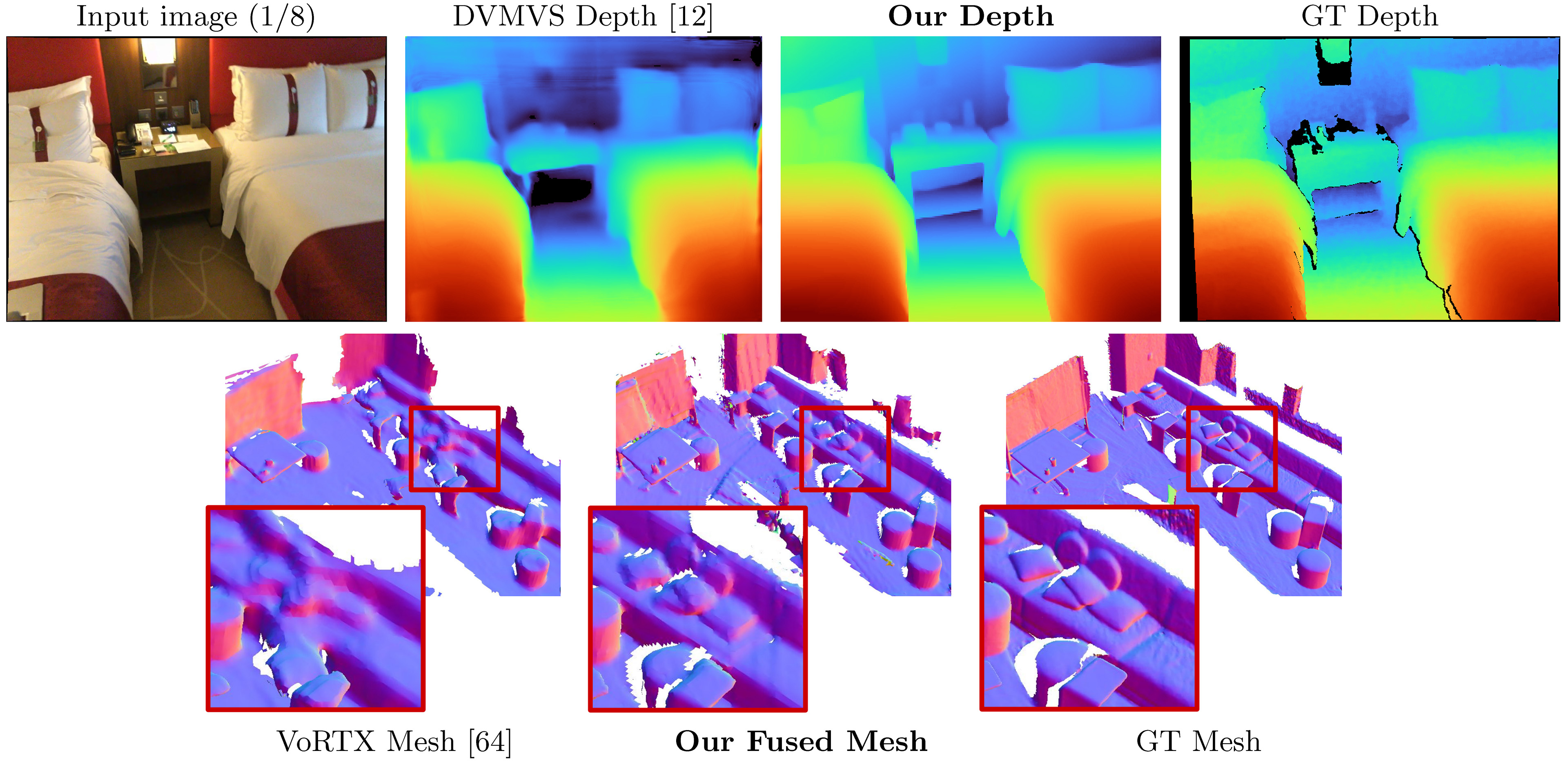
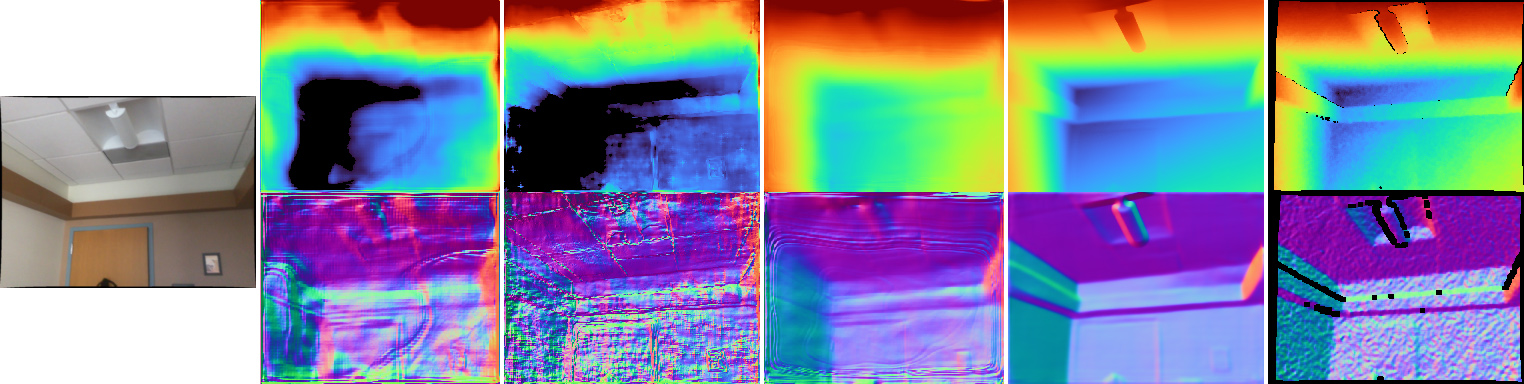
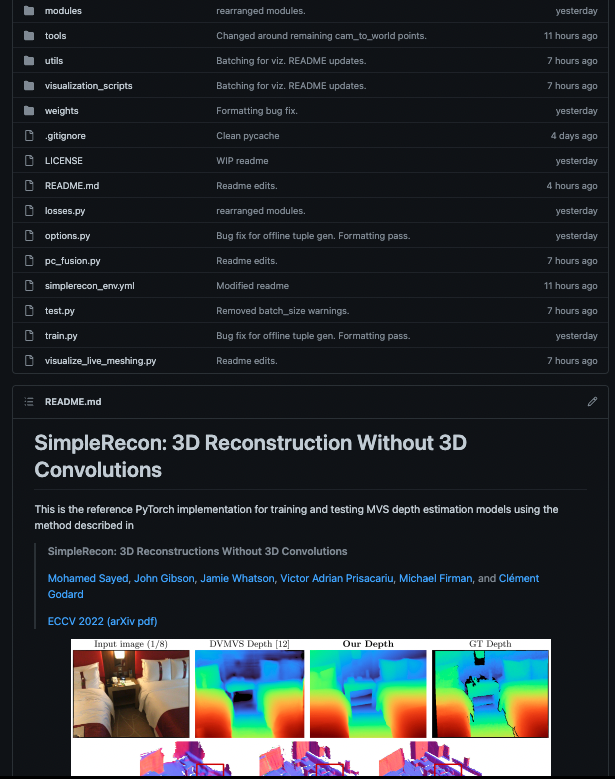
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-of-the-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction.
SimpleRecon is fast. Our batch size one performance is 70ms per frame. This makes accurate reconstruction via fast depth fusion possible!
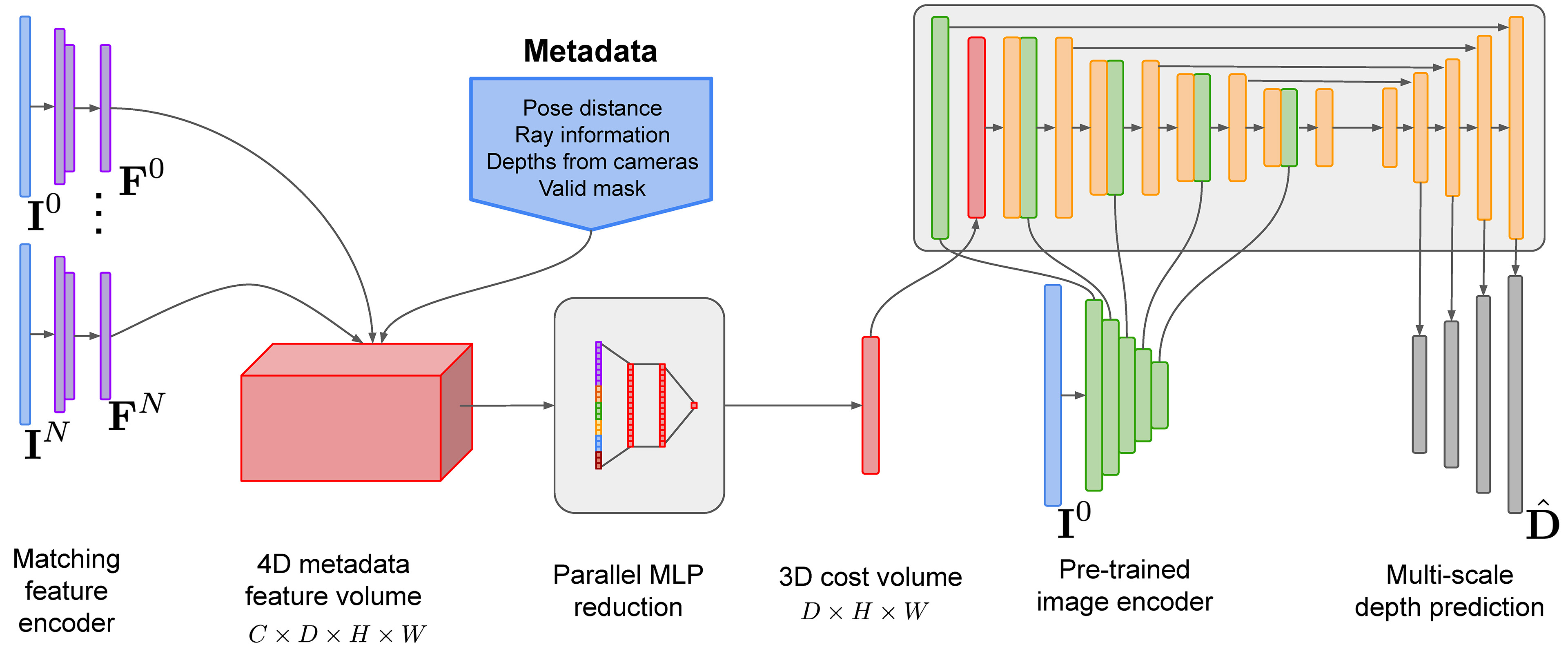
Our key contribution is the injection of cheaply-available metadata into the feature volume. Each volumetric cell is then reduced in parallel with an MLP into a feature map before input into a 2D cost volume encoder-decoder. We also make use of an image encoder specifically used to enforce a strong image prior when propagating and correcting depth estimates from the cost volume throughout the frame in the cost volume encoder-decoder.
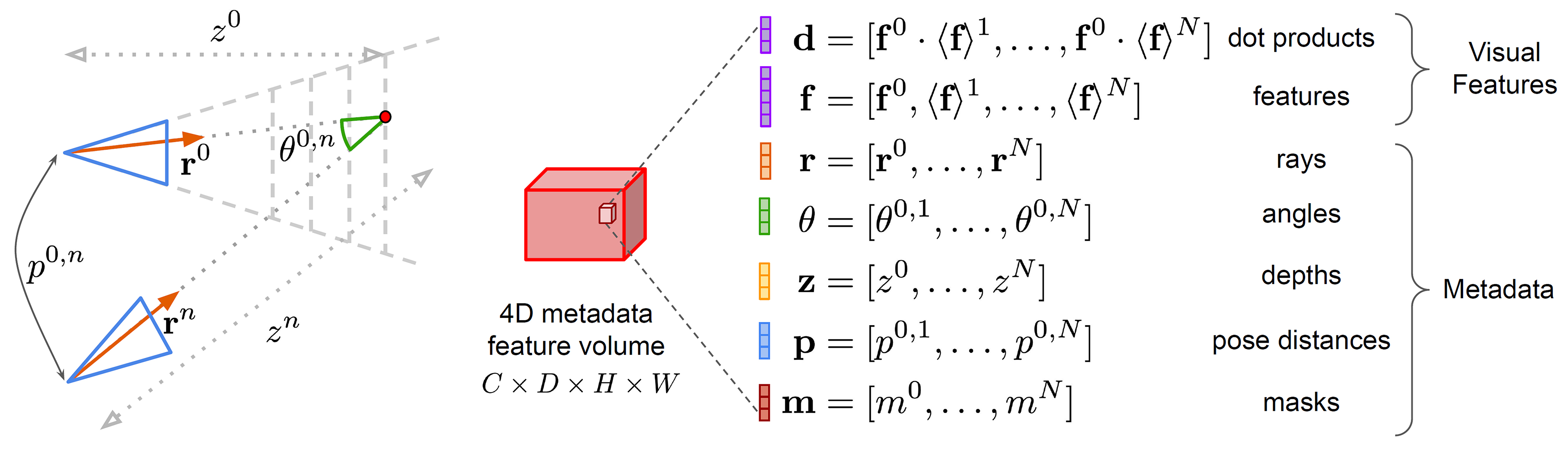
Metadata insertion Typical MVS systems predict depth from warped features or
differences between features \eg dot products. We additionally include cheaply-available metadata
for improved performance. Indices are omitted for clarity.






If you find this work useful for your research, please cite:
@inproceedings{sayed2022simplerecon,
title={SimpleRecon: 3D Reconstruction Without 3D Convolutions},
author={Sayed, Mohamed and Gibson, John and Watson, Jamie and Prisacariu, Victor and Firman, Michael and Godard, Cl{\'e}ment},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022},
}
We thank Aljaž Božič of TransformerFusion, Jiaming Sun of Neural Recon, and Arda Düzçeker of DeepVideoMVS for quickly providing useful information to help with baselines and for making their codebases readily available, especially on short notice.
The tuple generation scripts make heavy use of a modified version of DeepVideoMVS's Keyframe buffer (thanks again Arda and co!).
The PyTorch point cloud fusion module is borrowed from 3DVNet's repo. Thanks Alexander Rich!
We'd also like to thank Niantic's infrastructure team for quick actions when we needed them. Thanks folks!
Mohamed is funded by a Microsoft Research PhD Scholarship (MRL 2018-085).
© This webpage was in part inspired from this template.