Map-free Visual Relocalization:
Metric Pose Relative to a Single Image
ECCV 2024 Workshop & Challenge

The Map-free Visual Relocalization workshop investigates topics related to
metric visual relocalization relative to a single reference image instead of
relative to a map.
This problem is of major importance to many higher level applications, such as
Augmented/Mixed Reality, SLAM and 3D reconstruction.
It is important now, because both industry and academia are debating whether and
how to build HD-maps of the world for those tasks. Our community is working to
reduce the need for such maps in the first place.
We host the first Map-free Visual Relocalization Challenge 2024 competition with
two tracks:
map-free metric relative pose from a single image to a single image (proposed by
Arnold et al. in ECCV
2022) and from a query sequence to a single image (new).
While the former is a more challenging and thus interesting research topic, the
latter represents a more realistic relocalization scenario, where the system making
the queries may fuse information from query images and tracking poses over a short
amount of time and baseline.
We invite papers to be submitted to the workshop.
Schedule 🔗
📅 On Monday, 30th September, 2024, AM [Add to Google Calendar]
| Time | Event |
|---|---|
| 09:05 - 09:20 | Welcome introduction by Victor Adrian Prisacariu, Niantic and Oxford University |
| 09:25 - 09:55 | Jakob Engel, Meta Spatial AI for Contextual AI This talk focuses on Spatial AI for Contextual AI: How localization and 3D spatial scene understanding will enable the next generation of smart wearables and contextually grounded AI models. I will talk about recent research including map-free and vision-free localization for AR and smart glasses, as well as semantic scene- and user- understanding; as well as talk about some of the challenges that are left. |
| 10:00 - 10:30 | Eduard Trulls, Google Beyond visual positioning: how localization turned out to provide efficient training of neural, semantic maps What do you do if you built a system that incorporates the largest ground-level corpus of imagery into a large-scale localization system serving thousands of queries per second? You add overhead and semantic data and simultaneously re-think the problem from the ground up. In SNAP, localization becomes merely a side-task and the resulting maps start to encode scene semantics, motivating an entirely new set of applications and research directions. In this talk we will give a brief overview of how we moved away from further iterations on Google's Visual Positioning Service to break with the classic visual-localization approaches. SNAP is trained only using camera poses over tens of millions of StreetView images. The resulting algorithm can resolve the location of challenging image queries beyond the reach of traditional methods, outperforming the state of the art in localization by a large margin. More interestingly though, our neural maps encode not only geometry and appearance but also high-level semantics, discovered without explicit supervision. 📜 From VPS to SNAP (11MB) |
| 10:30 - 11:00 | Coffee break and poster session |
| 11:00 - 11:45 | Vincent Leroy,
Naver Labs Europe
and Single Frame challenge track winner talk Grounding Image Matching in 3D with MASt3R The journey from CroCo to MASt3R exemplify a significant paradigm shift in 3D vision technologies. This presentation will delve into the methodologies, innovations, and synergistic integration of these frameworks, demonstrating their impact on the field and potential future directions. The discussion aims to highlight how these advancements unify and streamline the processing of 3D visual data, offering new perspectives and capabilities in map-free visual relocalization, robotic navigation and beyond. 📜 Grounding Image Matching in 3D with MAStƎR (200 MB) |
| 11:50 - 12:20 | Torsten Sattler, CTU Prague Scene Representations for Visual Localization Visual localization is the problem of estimating the exact position and orientation from which a given image was taken. Traditionally, localization approaches either used a set of images with known camera poses or a sparse point cloud, obtained from Structure-from-Motion, to represent the scene. In recent years, the list of available scene representations has grown considerably. In this talk, we review a subset of the available representations. 📜 Scene Representations for Visual Localization (69 MB) |
| 12:25 - 12:55 | Shubham Tulsiani, CMU Rethinking Camera Parametrization for Pose Prediction Every student of projective geometry is taught to represent camera matrices via an extrinsic and intrinsic matrix and learning-based methods that seek to predict viewpoints given a set of images typically adopt this (global) representation. In this talk, I will advocate for an over-parametrized local representation which represents cameras via rays (or endpoints) associated with each image pixel. Leveraging a diffusion based model that allows handling uncertainty, I will show that such representations are more suitable for neural learning and lead to more accurate camera prediction. 📜 Rethinking Camera Parametrization for (Sparse-view) Pose Prediction (66 MB) |
| 12:55 - 13:00 |
Closing Remarks and award photos
|
Speakers 🔗

Jakob Engel, Meta
Talk title: Spatial AI for Contextual AI
Summary: This talk focuses on Spatial AI for Contextual AI: How
localization and 3D spatial scene understanding will enable the next generation of smart
wearables and contextually grounded AI models. I will talk about recent research including
map-free and vision-free localization for AR and smart glasses, as well as semantic scene- and
user- understanding; as well as talk about some of the challenges that are left.
Bio: Jakob Engel is a Director of Research at Meta Reality labs, where he is leading egocentric machine perception research as part of Meta’s Project Aria. He has 10+ years of experience working on SLAM, 3D scene understanding and user/environment interaction tracking, leading both research projects as well as shipping core localization technology into Meta’s MR and VR product lines. Dr. Engel received his Ph.D. in Computer Science at the Computer Vision Group at the Technical University of Munich in 2016, where he pioneered direct methods for SLAM through DSO and LSD-SLAM.

Vincent Leroy, Naver Labs Europe
Talk title: Grounding Image Matching in 3D with MASt3R
Slides:
📜 Grounding Image Matching in 3D with MAStƎR
(200 MB)
Summary: The journey from CroCo to MASt3R exemplify a
significant paradigm shift in 3D vision technologies. This presentation will delve into the
methodologies, innovations, and synergistic integration of these frameworks, demonstrating their
impact on the field and potential future directions. The discussion aims to highlight how these
advancements unify and streamline the processing of 3D visual data, offering new perspectives
and capabilities in map-free visual relocalization, robotic navigation and beyond.
Bio: Vincent is a research scientist in Geometric Deep Learning at Naver Labs Europe. He joined 5 years ago, in 2019, after completing his PhD on Multi-View Stereo Reconstruction for dynamic shapes at the INRIA Grenoble-Alpes under the supervision of E. Boyer and J-S. Franco. Other than that, he likes hiking in the mountains and finding simple solutions to complex problems. Interestingly, the latter usually comes with the former.

Torsten Sattler, CTU Prague
Talk title: Scene Representations for Visual Localization
Slides:
📜 Scene Representations for Visual Localization (69 MB)
Summary: Visual localization is the problem of estimating the
exact position and orientation from which a given image was taken. Traditionally, localization
approaches either used a set of images with known camera poses or a sparse point cloud, obtained
from Structure-from-Motion, to represent the scene. In recent years, the list of available scene
representations has grown considerably. In this talk, we review a subset of the available
representations.
Bio: Torsten Sattler is a Senior Researcher at CTU. Before, he was a tenured associate professor at Chalmers University of Technology. He received a PhD in Computer Science from RWTH Aachen University, Germany, in 2014. From Dec. 2013 to Dec. 2018, he was a post-doctoral and senior researcher at ETH Zurich. Torsten has worked on feature-based localization methods [PAMI’17], long-term localization [CVPR’18, ICCV’19, ECCV’20, CVPR’21] (see also the benchmarks at visuallocalization.net), localization on mobile devices [ECCV’14, IJRR’20], and using semantic scene understanding for localization [CVPR’18, ECCV’18, ICCV’19]. Torsten has co-organized tutorials and workshops at CVPR (’14, ’15, ’17-’20), ECCV (’18, ’20), and ICCV (’17, ’19), and was / is an area chair for CVPR (’18, ’22, ’23), ICCV (’21, ’23), 3DV (’18-’21), GCPR (’19, ’21), ICRA (’19, ’20), and ECCV (’20). He was a program chair for DAGM GCPR’20, a general chair for 3DV’22, and will be a program chair for ECCV’24.

Eduard Trulls, Google
Talk title: Beyond visual positioning: how localization turned
out to provide efficient training of neural, semantic maps
Slides:
📜 From VPS to SNAP (11MB)
Summary: What do you do if you built a system that incorporates
the largest ground-level corpus of imagery into a large-scale localization system serving
thousands of queries per second? You add overhead and semantic data and simultaneously re-think
the problem from the ground up. In SNAP,
localization becomes merely a side-task and the resulting maps start to encode scene semantics,
motivating an entirely new set of applications and research directions. In this talk we will
give a brief overview of how we moved away from further iterations on Google's Visual
Positioning Service to break with the classic visual-localization approaches. SNAP is trained
only using camera poses over tens of millions of StreetView images. The resulting algorithm can
resolve the location of challenging image queries beyond the reach of traditional methods,
outperforming the state of the art in localization by a large margin. More interestingly though,
our neural maps encode not only geometry and appearance but also high-level semantics,
discovered without explicit supervision.
Bio: Eduard Trulls is a Research Scientist at Google Zurich, working on Machine Learning for visual recognition. Before that he was a post-doc at the Computer Vision Lab at EPFL in Lausanne, Switzerland, working with Pascal Fua. He obtained his PhD from the Institute of Robotics in Barcelona, Spain, co-advised by Francesc Moreno and Alberto Sanfeliu. Before his PhD he worked in mobile robotics.

Shubham Tulsiani, Carnegie Mellon University
Talk title: Rethinking Camera Parametrization for Pose
Prediction
Slides:📜 Rethinking Camera Parametrization for (Sparse-view) Pose Prediction
(66 MB)
Summary: Every student of projective geometry is taught to
represent camera matrices via an extrinsic and intrinsic matrix and learning-based methods that
seek to predict viewpoints given a set of images typically adopt this (global) representation.
In this talk, I will advocate for an over-parametrized local representation which represents
cameras via rays (or endpoints) associated with each image pixel. Leveraging a diffusion based
model that allows handling uncertainty, I will show that such representations are more suitable
for neural learning and lead to more accurate camera prediction.
Bio: Shubham Tulsiani is an Assistant Professor at Carnegie Mellon University in the Robotics Institute. Prior to this, he was a research scientist at Facebook AI Research (FAIR). He received a PhD. in Computer Science from UC Berkeley in 2018 where his work was supported by the Berkeley Fellowship. He is interested in building perception systems that can infer the spatial and physical structure of the world they observe. He was the recipient of the Best Student Paper Award in CVPR 2015.

Victor Adrian Prisacariu, Niantic and Oxford University
Talk title: TBC (opening remarks)
Bio: Professor Victor Adrian Prisacariu received the Graduate
degree (with first class hons.) in computer engineering from Gheorghe Asachi Technical
University, Iasi, Romania, in 2008, and the D.Phil. degree in engineering science from the
University of Oxford in 2012.
He continued here first as an EPSRC prize Postdoctoral
Researcher, and then as a Dyson Senior Research Fellow, before being appointed an Associate
Professor in 2017.
He also co-founded 6D.ai, where he built
APIs to help developers augment reality in ways that users would find meaningful, useful and
exciting. The 6D.ai SDK used a standard built-in smartphone camera to build a cloud-based,
crowdsourced three-dimensional semantic map of the world all in real-time, in the background.
6D.ai was acquired by Niantic in March 2020. He is now Chief Scientist with Niantic.
Victor's research interests include semantic visual tracking, 3-D reconstruction, and SLAM.
Confirmed posters 🔗
-
Grounding Image Matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon and Jérôme Revaud
Naver Labs Europe - Improving Map-Free Localization with Depth Supervision
Hitesh Jain and Sagar Verma
Granular AI -
Mismatched: Evaluating the
Limits of Image Matching Approaches and Benchmarks
Sierra Bonilla, Chiara Di Vece, Rema Daher, Xinwei Ju, Danail Stoyanov, Francisco Vasconcelos, Sophia Bano
University College London -
NeRF-Supervised Feature Point Detection and Description
Ali Youssef, Fransisco Vasconcelos
University College London -
CrossScore: Towards Multi-View Image Evaluation and Scoring
Zirui Wang, Wenjing Bian, Victor Adrian Prisacariu
University of Oxford
🏆 2024 Challenge Winners 🔗
Single Frame (Leaderboard)
"MASt3R (Ess.Mat + D.Scale)"
"interp_metric3d_loftr_3d2d"

"Mickey Variant GT_Depth"
Multi Frame (Leaderboard)
No accepted entries.Prizes 🔗
$6000 in prizes will be divided between the top submissions of the two tracks.
Niantic is also seeking partners from the growing community to co-fund and co-judge
the prizes.
About the Challenge 🔗
We have extended the Map-free benchmark for the challenge with a sequence-based
scenario, based on feedback from senior community members.
Therefore, the challenge consists of two tracks:
1. The original, single query frame to single map
frame task published
with the ECCV 2022 paper;
2. A new task with multiple query frames (9) and their
mobile device provided, metric tracking poses.
1. Single query frame to a single "map" frame
To recap, the task in the first track consists of from a single query image predict the metric relative pose to a single map image without any further auxiliary information.
2. Multiple query frames (9) to a single "map" frame
The second track is motivated by the observation that a burst of images, capturing
small motion, can be recorded while staying true to the map-free scenario: No
significant data capture or exploration of the environment.
At the same time, the burst of images allows the application of multi-frame depth
estimation and contains strong hints about the scene scale from the IMU sensor on
device.
We created a second version of the test set and leaderboard
for this track.
Stay up to date! 🔗
Please register your interest here, so we can keep you notified about news and updates!
Important Dates 🔗
- Challenge start
-
- 21st May, 2024
- Workshop paper and extended abstracts submission deadline
-
- 2nd August, 2024
- Workshop paper and extended abstracts camera-ready deadline
-
- 22nd August, 2024
- Challenge end
-
- 23rd August, 2024
- Challenge submission method description deadline
-
- 27th August, 2024
- Challenge winners announcement
-
- 30th August, 2024
- Workshop date (ECCV'24)
-
- 30th September, 2024, AM
Location 🔗
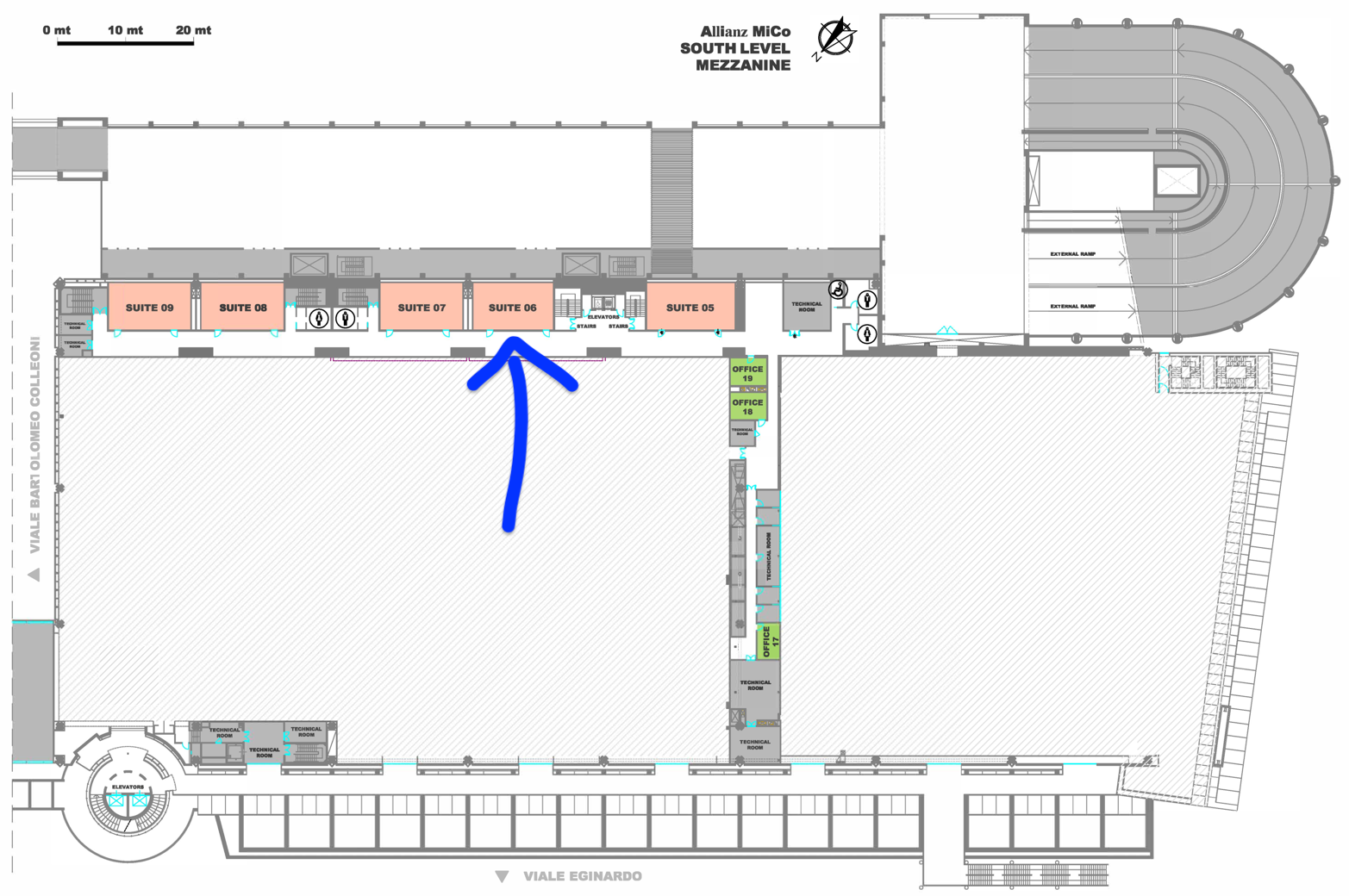
🏤📍 Suite 6, South Level Mezzanine Google Maps to Suite 6, Mezzanine, South Wing
Allianz MiCo • Milano Convention CentreViale Eginardo - Gate 2 (Or Piazzale Carlo Magno) – Gate 16 (for those arriving from Domodossola Metro Station)
20149 Milano, Italy
Call for Papers: ECCV Map-free Visual Relocalization Workshop & Challenge 2024 🔗
We invite submissions of workshop papers and extended abstracts to the ECCV Map-free Visual Relocalization Workshop & Challenge 2024. This workshop aims to advance the field of visual relocalization without relying on pre-built maps. The following topics and related areas are of interest:
- visual relocalization,
- feature-matching,
- pose regression (absolute and relative),
- depth estimation (monocular and multi-frame),
- scale estimation,
- confidence and uncertainty,
- structure-from-motion
Workshop paper and extended abstract submission deadline: 2nd August, 2024. See also Important Dates.
Sign up through the contact form to stay up to date with future announcements.
🏆 Accepted Papers (pre-prints!) 🔗
Here follows a list of pre-prints of the three workshop papers accepted to the ECCV Map-free Visual Relocalization Workshop & Challenge 2024:
Submission Guidelines 🔗
1. Workshop paper 🔗
- Deadline: 2nd August, 2024.
- Follow the ECCV paper submission policies.
- Use the same format as for submissions to the main conference: official ECCV 2024 template.
- Accepted workshop papers should follow the ECCV paper chairs' guidance.
They will most likely communicate to use the official Springer ECCV 2024 template for the camera-ready version. - Evaluation on the Niantic Map-free Relocalization Dataset is encouraged but not required.
- Please submit at the workshop CMT
submission portal.
Use the "Workshop paper track" category under "Subject areas".
2. Extended abstract 🔗
- Deadline: 2nd August, 2024.
- Extended abstracts are not subject to the ECCV rules, so they can be in any template (e.g., ECCV or CVPR).
- The maximum length of extended abstracts excluding references is the equivalent
of 4 pages in the official CVPR 2024 format.
- Extended abstracts can include already published or accepted works, as they are meant to provide authors with the possibility to showcase their ongoing research in areas relevant to map-free relocalization.
- Extended abstracts will not be included in the conference proceedings, do not count as paper publication.
- However, the authors of accepted extended abstracts will get the opportunity to present their work at the workshop poster session.
- Examples of extended abstracts:
Accepted Extended Abstracts from HANDS @ ECCV 2022
. E.g.,
Scalable High-fidelity 3D Hand Shape Reconstruction via Graph Frequency Decomposition. Tianyu Luan, Jingjing Meng, Junsong Yuan. [pdf] -
Please submit at the workshop CMT
submission portal.
Use the "Extended abstract track" category under "Subject areas".
3. Method description (~technical report) 🔗
- Challenge leaderboard entry deadline: 23rd August, 2024.
- Method description publication deadline: 27th August, 2024.
- The minimum required for valid competition entries.
- Accepted workshop papers or accepted extended abstracts also qualify as valid method descriptions, no need to submit more.
-
Must be publicly available on ArXiv or equivalent.
If there are delays with an ArXiv publication, please send us proof of pending submission. - This can be a non-peer reviewed paper in any format (e.g., ECCV or CVPR). The method description has to contain sufficient detail for replication of the leaderboard entry's results.
Competition Requirements 🔗
- Entries must be submitted within the competition time limits: 21st May, 2024 - 23rd August, 2024.
- Entries in the leaderboard that were submitted before the 21st May, 2024 will not be considered as participating in the 2024 Map-free Visual Relocalization challenge.
- Entries in the leaderboard must point to a valid method description (as outlined above under "3. Method description").
FAQ 🔗
- Q:
- I would like to participate in the challenge, and I don't have a paper yet for my method. What should I do?
- A:
-
You should submit a workshop paper
or an extended abstract to the workshop,
or make a method description available on ArXiv.
Upon acceptance, your leaderboard entry should refer to the accepted submission.
If rejected, make sure to have a method description available on ArXiv to keep your leaderboard entry valid.
Make sure your leaderboard entry dates between the competition start and end dates (21st May, 2024 - 23rd August, 2024).
- Q:
- I would like to participate in the challenge with a method I have already published. What should I do?
- A:
-
Make sure your leaderboard entry dates between the competition start and end
dates (21st May, 2024 - 23rd August, 2024).
Your leaderboard entry should point to a valid method description, e.g., the link to your published paper.
- Q:
- I would like to participate in the challenge with a method I have already published, but I've made some changes to the method specific to the challenge. What should I do?
- A:
- You probably should submit an
extended abstract to the workshop or
make a method description available on
ArXiv, citing your original work.
Resubmitting your original work without sufficient amount of differences compared to the already submitted or published version might violate the ECCV policy regarding dual submissions.
Make sure your leaderboard entry dates between the competition start and end dates (21st May, 2024 - 23rd August, 2024).
Your leaderboard entry should refer to a valid method description, e.g., the title of the extended abstract or the link to your method description on ArXiv.
- Q:
-
I don't want to participate in the challenge, but I have a paper that has not
been published anywhere else and is not currently under review anywhere.
Can I submit it to the workshop? - A:
- Yes! Submit it as a workshop paper
on the workshop
CMT.
We encourage you to update the paper with evaluation on the Niantic Map-free Relocalization Dataset, but it is not required.
If your method can solve the task in the challenge, you should consider also submitting it to the leaderboard.
We look forward to your contributions advancing the field of map-free visual
relocalization.
For any questions or clarifications, please contact the workshop
organizers.








